
Your Error Taxonomy Is Your Governance Model
Why “what can go wrong” is the fastest way to earn trust

Most institutional AI teams can describe what their system can do.
Far fewer can describe what it does when it is wrong.
That gap is the reason pilots stall.
When reviewers ask hard questions, they are not trying to be difficult. They are trying to locate the system’s failure posture.
What happens when it produces the wrong answer?
What happens when it cites the wrong source?
What happens when it invents a policy interpretation?
What happens when a user follows a bad recommendation?
What happens when it outputs something inappropriate for the workflow?
If you cannot answer those in a structured way, you will keep getting stuck in the same loop:
More questions. More meetings. More hesitancy.
Because the institution cannot tell whether you have a governable system or a clever demo.
An error taxonomy fixes that.
Not because it makes the system perfect.
Because it makes failure legible, owned, and controllable.
In institutions, that is what earns approval.
The institutional problem framing
Pilots rarely fail because they are useless.
They fail because they are indefensible.
Defensibility is not about never being wrong. It is about having a system for what happens when you are wrong.
Reviewers are accountable for:
harm to constituents
operational mistakes
reputational risk
legal exposure
audit scrutiny
When you show up with a system that has no defined failure categories, no severity thresholds, and no owner response posture, reviewers assume the worst.
They assume that when something goes wrong, the team will improvise.
Institutions do not approve improvisation at scale.
The misframe
The misframe is treating errors as a model quality problem.
As if you just need to tune prompts, raise accuracy, and reduce hallucinations.
That is a technical framing.
Reviewers are asking a governance question:
What kinds of errors matter, how will we detect them, who will own them, and what happens next?
A second misframe is thinking an error taxonomy is a spreadsheet for data science teams.
It is not.
An error taxonomy is a decision system.
It is how you decide:
what requires escalation
what requires immediate pause
what can be corrected in workflow
what must be logged
what triggers a governance update
If you have no taxonomy, you have no shared standard. And if you have no shared standard, review becomes political.
The governing model
Here is the model.
Your error taxonomy is your governance model because it defines:
what failure looks like
who owns it
how the institution responds
what gets recorded
what changes as a result
A good taxonomy does three things at once:
makes risk legible without fear theater
creates consistent reviewer behavior
turns exceptions into governance learning
Most importantly, it prevents the most dangerous failure mode:
Silent errors that never become system improvement.
Implementation notes
If you want this to work inside a real institution, keep it scoped, concrete, and owned.
1) Start with the workflow, not the model
Do not build a universal taxonomy for “AI in the organization.”
Build it for one workflow:
one set of users
one outcome
one review cadence
one operating record
You can expand later. But a taxonomy that is too broad becomes theoretical, and theory does not survive procurement.
2) Define a small set of error classes
Most teams either do too little or too much.
Too little: “wrong answer”
Too much: 47 categories no one uses
Start with six to eight error classes that map to real institutional risk.
Examples:
wrong or unsupported claim
incorrect citation or source mismatch
policy misinterpretation
privacy or sensitive data leakage
inappropriate tone or content
workflow unsafe recommendation
missing context or incomplete output
refusal when action is required
3) Add severity tiers that match institutional reality
Not all errors are equal.
Institutions need to know which errors:
can be corrected locally
require escalation
require pause
A simple three tier approach works well:
Severity 1: Correctable
Fix in workflow, log for pattern review.
Severity 2: Escalate
Escalate to domain owner or risk partner, log, require response.
Severity 3: Stop and govern
Pause the workflow category, require governance update before resuming.
4) Assign owners by category
Ownership is where governance becomes real.
Every error class must have:
a responsible owner for handling the event
an accountable owner for updating the governance posture
If ownership is unclear, errors will be handled inconsistently, which destroys trust faster than the error itself.
5) Tie it to the decision trace
An error taxonomy without a log is a poster.
A taxonomy becomes governance when it is connected to:
an exception log
a weekly pattern review
a change control process
That is how errors become system improvement instead of repeated drama.
Artifact insert: Error Taxonomy Table (starter)
Use this table as the minimal version. It is designed to be adopted, not admired.
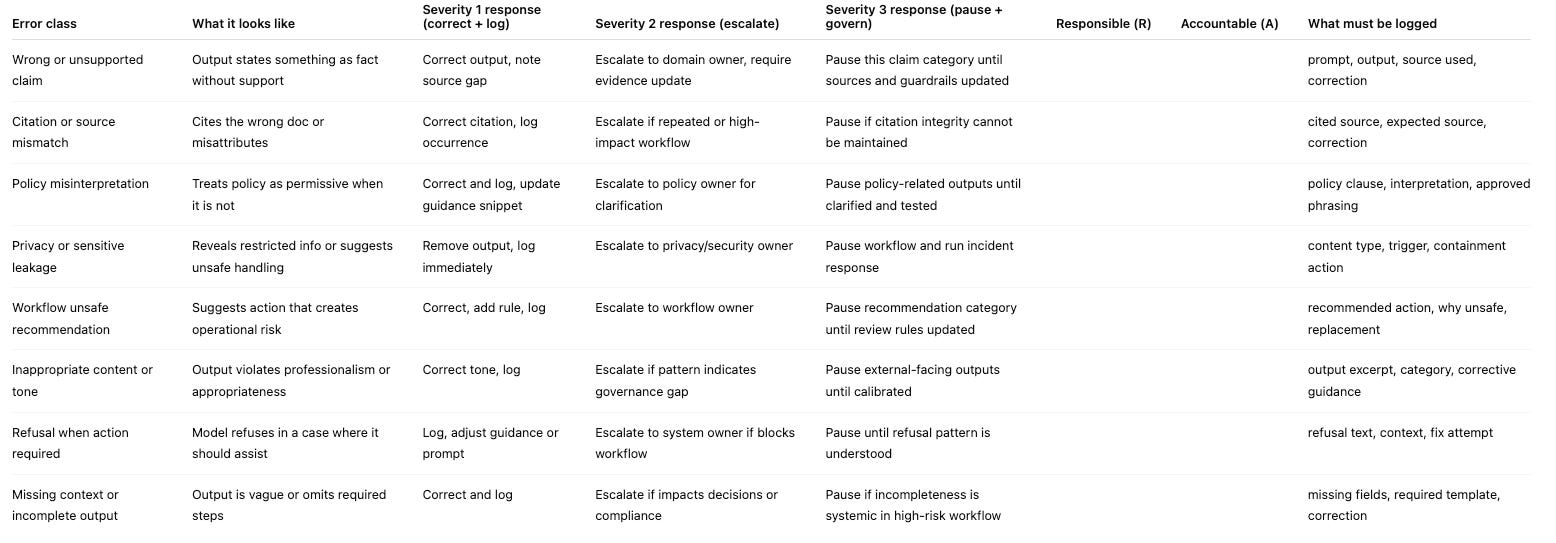
Fill this out with actual names. If you cannot fill out R and A, that is not a documentation gap. That is an approval gap.
Risks and controls
Risk: Taxonomy theater
You create the table, but no one uses it.
Control: Tie it to the reviewer workflow, require logging for Severity 2 and 3, and review patterns weekly.
Risk: Everything becomes Severity 3
Teams panic and pause too often, creating stall.
Control: Define Severity 1 as the default, and reserve Severity 3 for specific, named conditions.
Risk: Errors get handled privately
The system never learns, and trust decays silently.
Control: No private exception handling for Severity 2 and 3. All events require a decision trace.
Risk: Taxonomy drift
New error classes appear in practice, but governance never updates.
Control: Add a weekly “taxonomy maintenance” step to the operating cadence.
What to do next
If you are running a pilot, do this this week:
Choose six error classes that match your workflow risk.
Define three severity tiers with clear triggers.
Assign responsible and accountable owners for each class.
Start an exception log tied to the taxonomy.
Review patterns weekly and route changes through change control.
You do not need perfection to earn trust.
You need ownership, consistency, and a trace.
That is what institutions approve.
Reply with your workflow and your top failure mode. I will suggest a minimal error taxonomy and severity posture that fits your environment.
Educational guidance only, not legal advice. Confirm with your internal legal, procurement, and security reviewers before acting on any policy or compliance implications.